Cache Implementation Guide¶
This document describes how the Gemini prompt caching system works internally. For configuration and usage, see Observability & Metrics.
Architecture Overview¶
Visual Architecture Diagrams¶
Request Flow Diagram¶
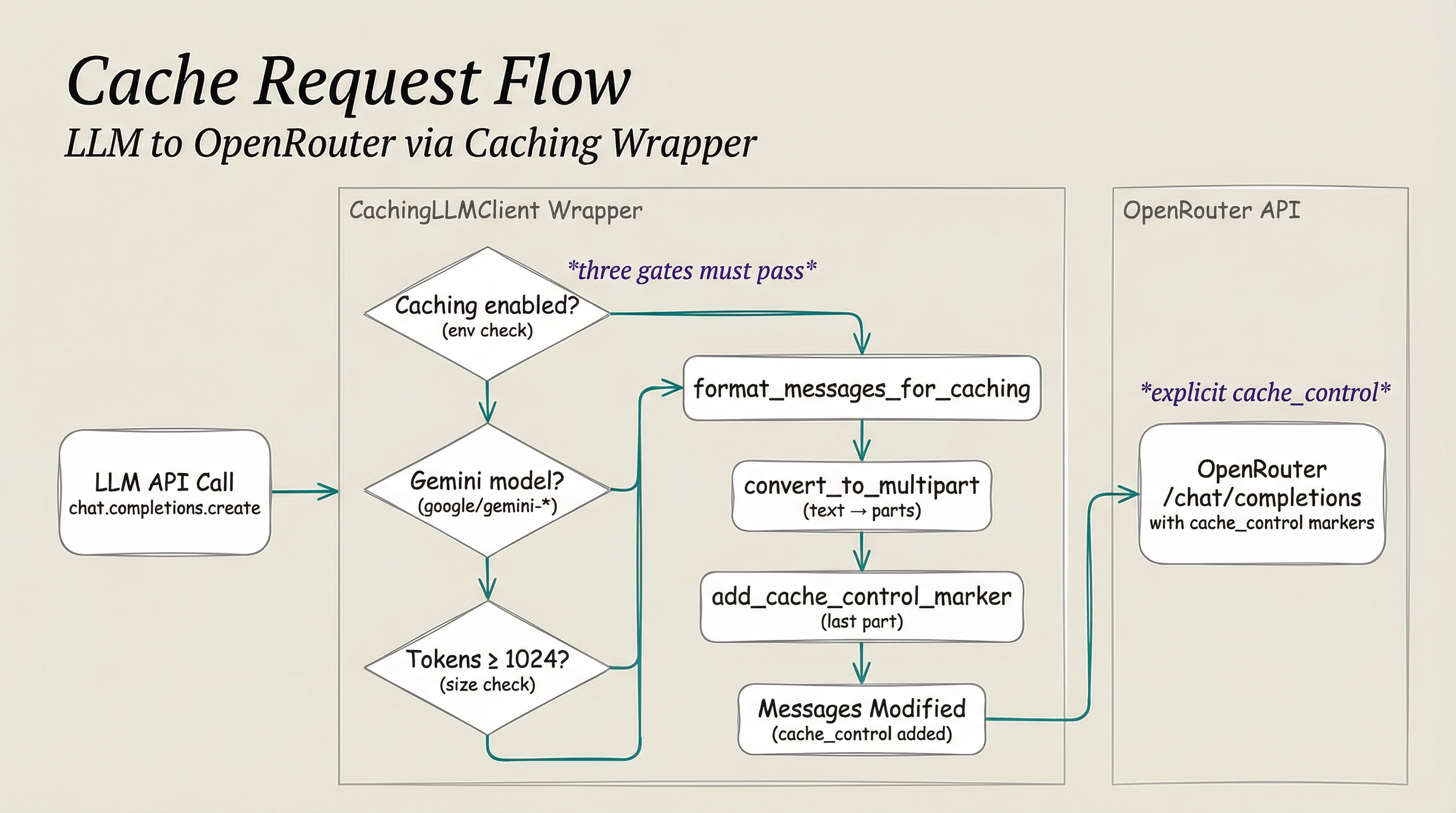
LLM requests flow through the CachingLLMClient wrapper, which checks three conditions before applying cache_control markers and forwarding to OpenRouter.
Component Architecture¶
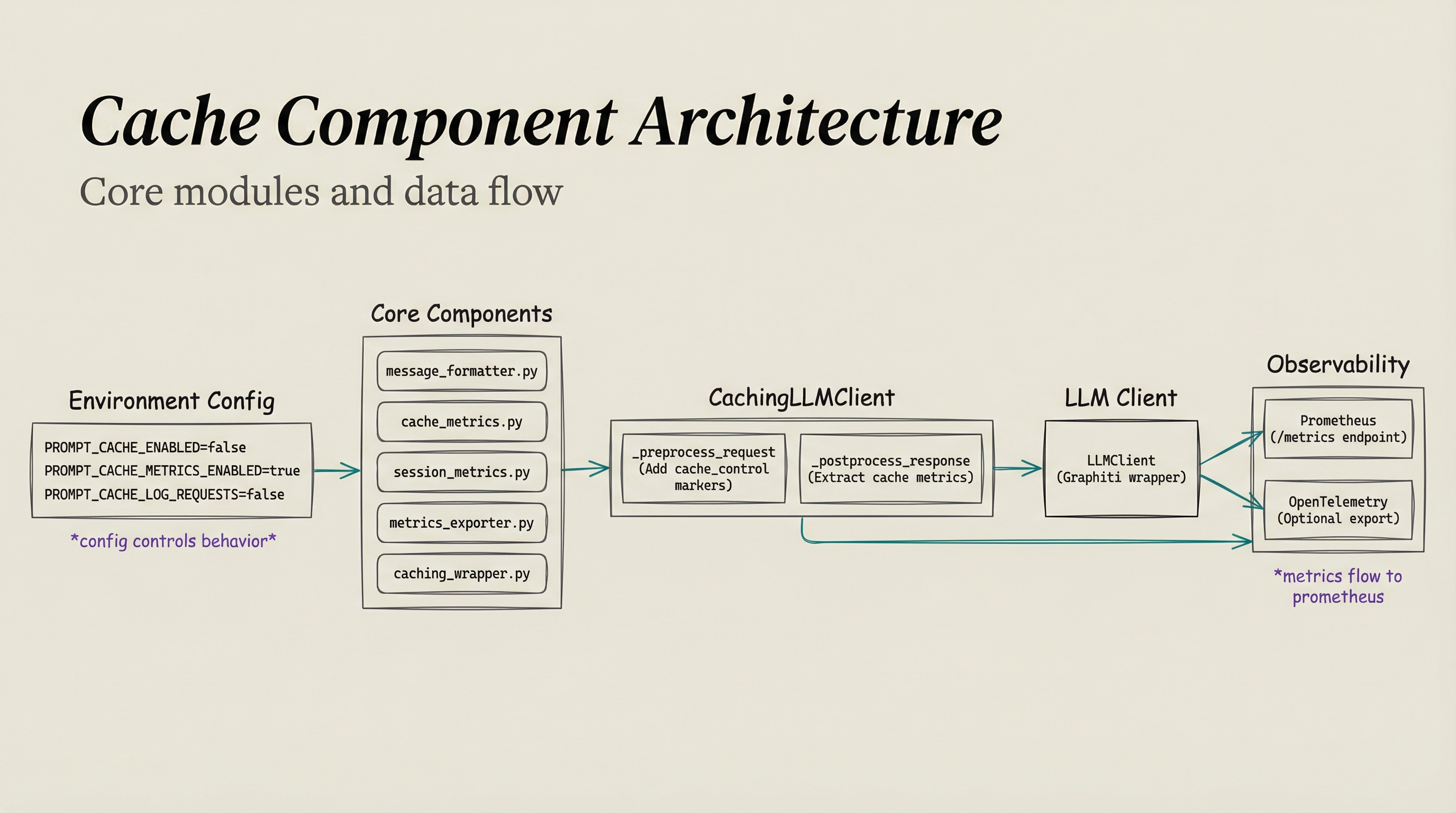
Core modules work together: environment configuration controls behavior, core components power the caching wrapper, which wraps the LLM client and exports metrics to Prometheus.
Decision Tree: When is Caching Applied?¶
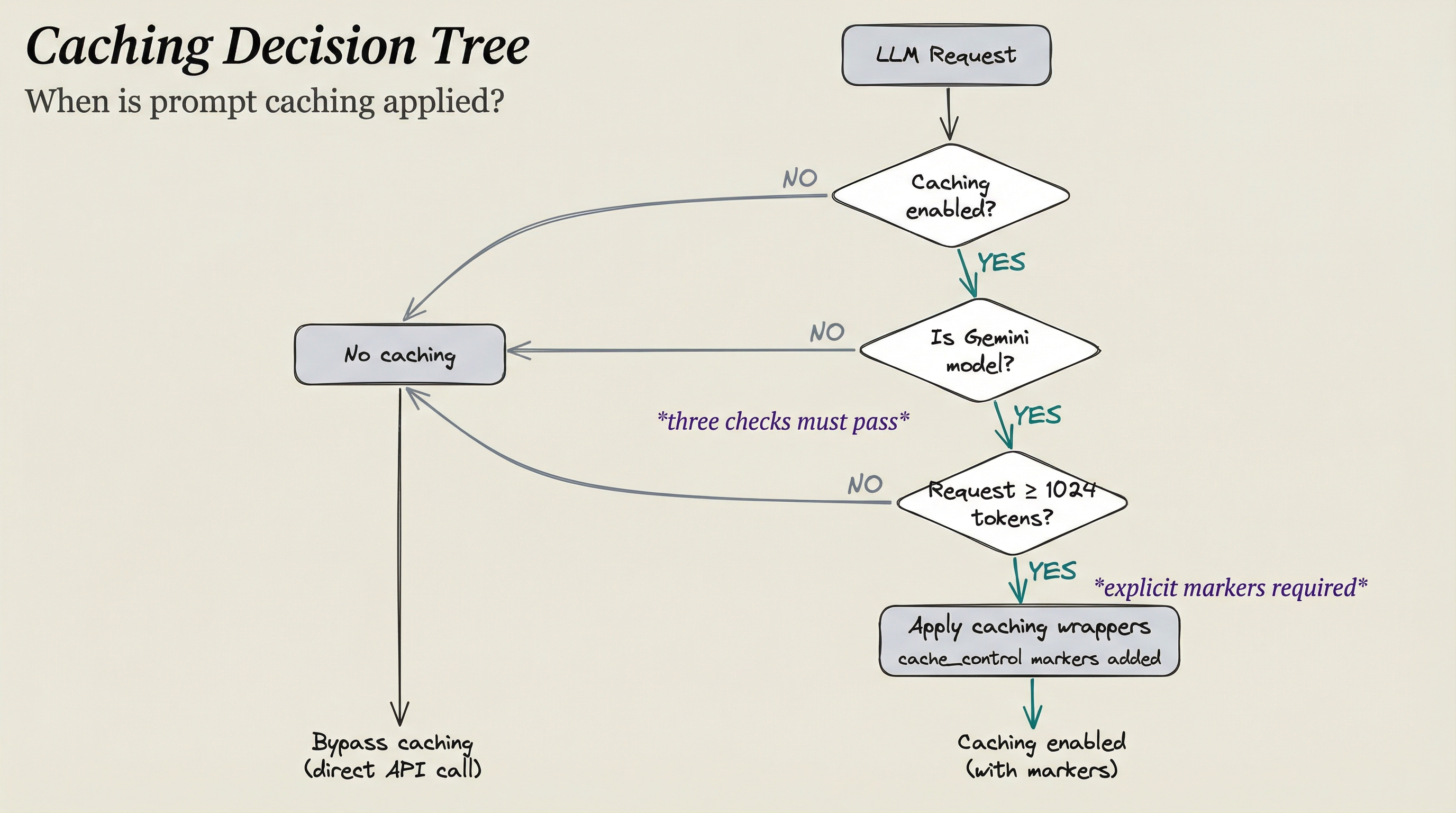
Three checks must pass: caching enabled, Gemini model, and sufficient token count. If any check fails, the request bypasses caching.
Metrics Flow¶
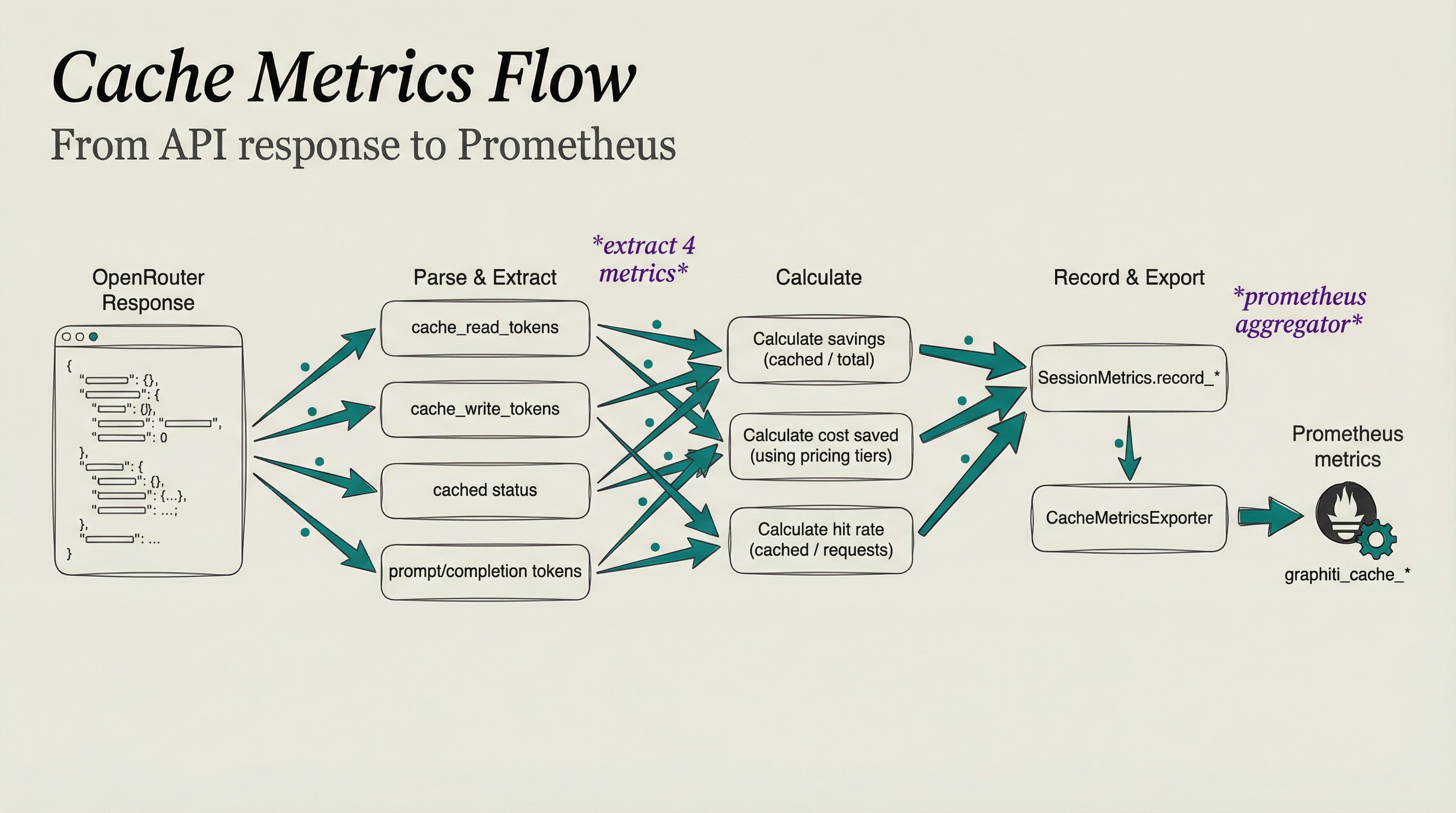
OpenRouter responses are parsed for cache metrics, calculated for savings and hit rates, recorded to SessionMetrics, and exported to Prometheus.
Complete Request Flow¶
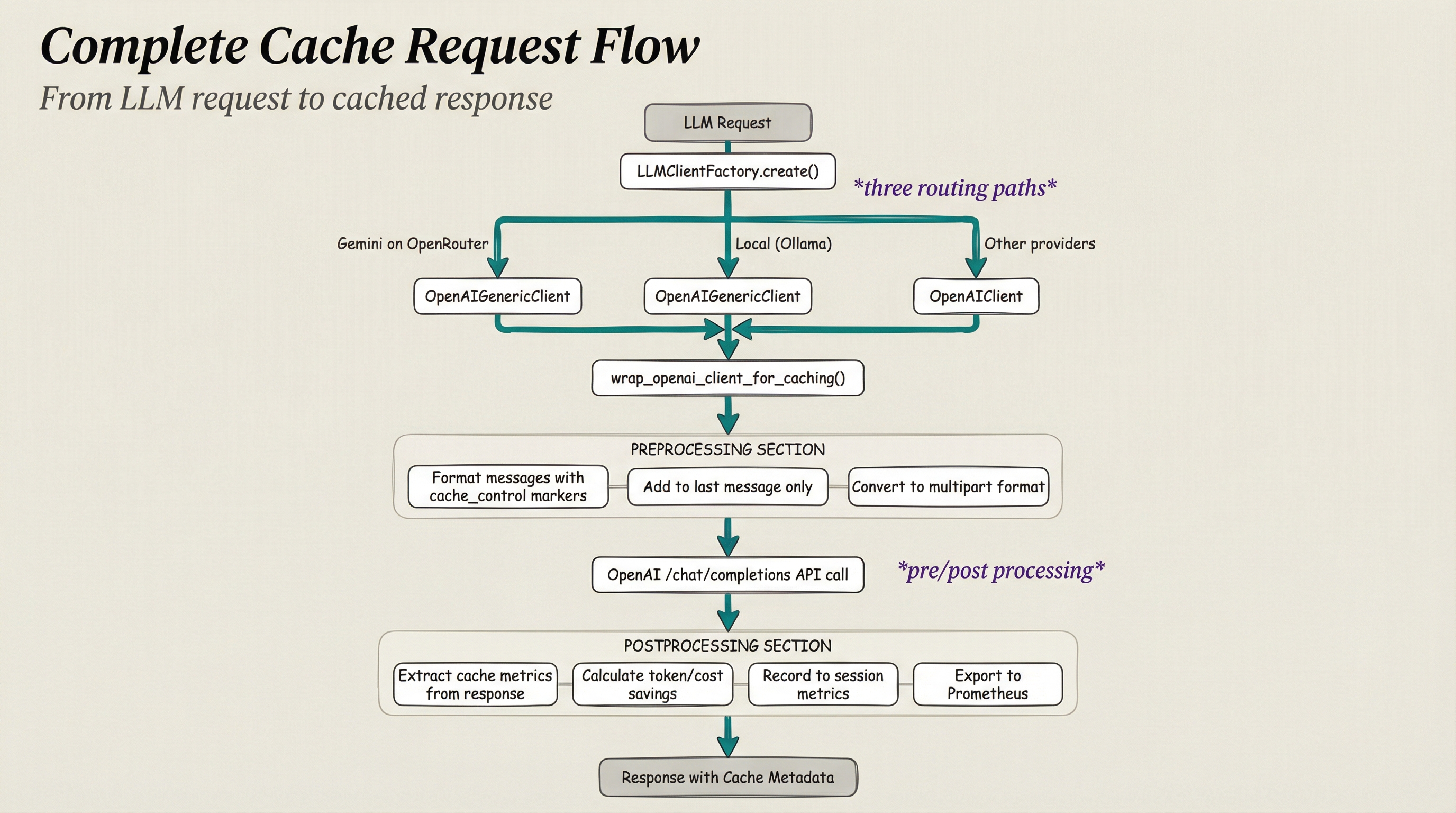
The complete flow from LLM request through client routing, caching wrapper, preprocessing, API call, and postprocessing with metrics extraction.
File Architecture¶
All cache implementation files live in docker/patches/ following Constitution Principle VII (Language Separation): Python code in docker/, TypeScript code in src/.
| File | Purpose | Key Exports |
|---|---|---|
factories.py |
Client routing logic | LLMClientFactory.create() |
caching_wrapper.py |
Patches OpenAI client | wrap_openai_client_for_caching() |
message_formatter.py |
Adds cache_control markers | format_messages_for_caching() |
cache_metrics.py |
Per-request metrics | CacheMetrics, PricingTier |
session_metrics.py |
Session aggregation | SessionMetrics |
metrics_exporter.py |
Prometheus export | CacheMetricsExporter |
caching_llm_client.py |
Wrapper class | CachingLLMClient |
Client Routing¶
The critical design decision in this implementation: Gemini models on OpenRouter must use OpenAIGenericClient to route requests through /chat/completions instead of /responses.
Location: docker/patches/factories.py (lines 305-343)
# Simplified routing logic
if _is_gemini_model(config.model) and 'openrouter' in provider_name.lower():
# Use OpenAIGenericClient (routes to /chat/completions)
client = OpenAIGenericClient(config=llm_config)
if _caching_wrapper_available:
client = wrap_openai_client_for_caching(client, config.model)
return client
Why This Matters¶
| Endpoint | Multipart Format | Caching Works | Structured Output |
|---|---|---|---|
/responses |
Rejected | No | Yes |
/chat/completions |
Accepted | Yes | Yes (json_schema) |
The /responses endpoint returns "expected string, received array" when it receives multipart messages with cache_control markers. The /chat/completions endpoint accepts both multipart format AND json_schema for structured outputs.
Message Formatting¶
Location: docker/patches/message_formatter.py
The formatter converts messages to multipart format and adds cache_control markers to the last message only.
Transformation Example¶
Input (standard format):
Output (multipart with cache_control):
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are an AI assistant...",
"cache_control": {"type": "ephemeral", "ttl": "1h"}
}
]
}
Why Mark Only the Last Message?¶
The cache_control marker tells Gemini "everything up to and including this point should be cached." By marking the last message:
- System prompts and context (earlier messages) become part of the cached prefix
- First request creates the cache (pays full price)
- Subsequent requests with the same prefix get 90% discount on cached tokens
Processing Functions¶
| Function | Purpose |
|---|---|
is_caching_enabled() |
Checks MADEINOZ_KNOWLEDGE_PROMPT_CACHE_ENABLED |
is_gemini_model(model) |
Pattern matches "google/gemini" |
is_cacheable_request(messages) |
Heuristic: minimum ~1024 tokens |
convert_to_multipart(message) |
Converts string content to array format |
add_cache_control_marker(message) |
Adds {"type": "ephemeral", "ttl": "..."} |
format_messages_for_caching(messages, model) |
Main entry point |
Metrics Data Models¶
CacheMetrics (Per-Request)¶
Location: docker/patches/cache_metrics.py
@dataclass
class CacheMetrics:
cache_hit: bool # Was cache used?
cached_tokens: int # Tokens served from cache
prompt_tokens: int # Total input tokens
completion_tokens: int # Output tokens
tokens_saved: int # Alias for cached_tokens
cost_without_cache: float # Hypothetical cost (USD)
actual_cost: float # Real cost after discount
cost_saved: float # Dollar savings
savings_percent: float # Reduction percentage (0-100)
model: str # Model identifier
Cost Calculation¶
# Cost without cache (all tokens at full rate)
cost_without_cache = (prompt_tokens * input_rate) + (completion_tokens * output_rate)
# Actual cost (cached tokens at 90% discount)
uncached_tokens = prompt_tokens - cached_tokens
actual_cost = (uncached_tokens * input_rate) + \
(cached_tokens * cached_input_rate) + \
(completion_tokens * output_rate)
# Savings
cost_saved = cost_without_cache - actual_cost
Pricing Tiers¶
| Model | Input (per 1M) | Cached (90% off) | Output (per 1M) |
|---|---|---|---|
| gemini-2.0-flash-001 | $0.10 | $0.01 | $0.40 |
| gemini-2.5-flash | $0.30 | $0.03 | $2.50 |
| gemini-2.5-pro | $1.25 | $0.125 | $10.00 |
SessionMetrics (Aggregated)¶
Location: docker/patches/session_metrics.py
Aggregates metrics across all requests in a session:
| Property | Type | Description |
|---|---|---|
total_requests |
int | Total API calls |
cache_hits |
int | Requests with cache_hit=true |
cache_misses |
int | Requests with cache_hit=false |
total_cached_tokens |
int | Sum of all cached_tokens |
total_cost_without_cache |
float | Cumulative hypothetical cost |
total_actual_cost |
float | Cumulative real cost |
total_cost_saved |
float | Total savings |
cache_hit_rate |
float | Calculated percentage (0-100) |
overall_savings_percent |
float | Overall cost reduction % |
The Caching Wrapper¶
Location: docker/patches/caching_wrapper.py
The wrapper monkey-patches chat.completions.create() to intercept requests and responses.
Request Processing¶
async def create_with_caching(*args, **kwargs):
# 1. PREPROCESSING: Format messages with cache_control
if 'messages' in kwargs:
kwargs['messages'] = format_messages_for_caching(
kwargs['messages'], model
)
# 2. TIMING: Measure request duration
start_time = time.monotonic()
response = await original_create(*args, **kwargs)
duration = time.monotonic() - start_time
# 3. POSTPROCESSING: Extract metrics
extract_and_record_metrics(response)
return response
Response Metric Extraction¶
The wrapper handles multiple response formats:
| Format | Source | Fields |
|---|---|---|
| OpenRouter (root-level) | response.native_tokens_cached |
native_tokens_cached, tokens_prompt, tokens_completion |
| OpenAI (usage object) | response.usage.cached_tokens |
cached_tokens, prompt_tokens, completion_tokens |
Known Limitation: responses.parse()¶
The responses.parse() endpoint does not support multipart format:
Solution: Caching is automatically skipped for responses.parse() calls. Only chat.completions.create() supports caching.
Prometheus Integration¶
Location: docker/patches/metrics_exporter.py
Initialization¶
The metrics exporter is initialized in graphiti_mcp_server.py:
if _metrics_exporter_available:
metrics_port = int(os.getenv("MADEINOZ_KNOWLEDGE_METRICS_PORT", "9090"))
metrics_enabled = os.getenv("MADEINOZ_KNOWLEDGE_PROMPT_CACHE_METRICS_ENABLED", "true")
initialize_metrics_exporter(enabled=metrics_enabled, port=metrics_port)
Exposed Metrics¶
Counters (Cumulative)¶
| Metric | Labels | Description |
|---|---|---|
graphiti_cache_hits_total |
model | Cache hit count |
graphiti_cache_misses_total |
model | Cache miss count |
graphiti_cache_tokens_saved_total |
model | Total cached tokens |
graphiti_cache_cost_saved_total |
model | Total $ saved |
graphiti_prompt_tokens_total |
model | Input tokens used |
graphiti_completion_tokens_total |
model | Output tokens used |
graphiti_api_cost_total |
model | Total API cost |
Gauges (Current Value)¶
| Metric | Labels | Description |
|---|---|---|
graphiti_cache_hit_rate |
model | Current hit rate % |
graphiti_cache_enabled |
none | 1=enabled, 0=disabled |
Histograms (Distributions)¶
| Metric | Description |
|---|---|
graphiti_prompt_tokens_per_request |
Input token distribution |
graphiti_api_cost_per_request |
Cost per request |
graphiti_llm_request_duration_seconds |
Response latency |
Example Output¶
# Cache hit rate gauge
graphiti_cache_hit_rate{model="google/gemini-2.0-flash-001"} 75.77
# Cache hits counter
graphiti_cache_hits_total{model="google/gemini-2.0-flash-001"} 1523
# Cost savings counter
graphiti_cache_cost_saved_total{model="google/gemini-2.0-flash-001"} 0.7584
Configuration Reference¶
| Variable | Default | Description |
|---|---|---|
MADEINOZ_KNOWLEDGE_PROMPT_CACHE_ENABLED |
false |
Enable/disable caching |
MADEINOZ_KNOWLEDGE_PROMPT_CACHE_TTL |
1h |
Cache TTL (5m or 1h) |
MADEINOZ_KNOWLEDGE_METRICS_PORT |
9090 |
Prometheus metrics port |
MADEINOZ_KNOWLEDGE_PROMPT_CACHE_METRICS_ENABLED |
true |
Enable metrics export |
MADEINOZ_KNOWLEDGE_PROMPT_CACHE_LOG_REQUESTS |
false |
Debug logging |
Testing¶
Test files follow Constitution Principle VII (Language Separation):
| Test File | Location | Purpose |
|---|---|---|
test_cache_metrics.py |
docker/tests/unit/ |
Cache metrics extraction |
test_session_metrics.py |
docker/tests/unit/ |
Session aggregation |
test_caching_e2e.py |
docker/tests/integration/ |
End-to-end workflow |
test_metrics_endpoint.py |
docker/tests/integration/ |
Prometheus endpoint |
Success Criteria¶
| Metric | Target |
|---|---|
| Token reduction from cache | 40%+ |
| Cache hit rate (after warmup) | 60%+ |
| Response time improvement | 25%+ faster |
Quick Reference¶
Dependency Graph¶
factories.py
→ wrap_openai_client_for_caching() [caching_wrapper.py]
→ format_messages_for_caching() [message_formatter.py]
→ extract_and_record_metrics()
→ CacheMetrics.from_openrouter_response() [cache_metrics.py]
→ SessionMetrics.record_request() [session_metrics.py]
→ metrics_exporter.record_*() [metrics_exporter.py]
Key Design Decisions¶
| Decision | Rationale |
|---|---|
| OpenAIGenericClient routing | /responses rejects multipart; /chat/completions supports both |
| Mark only last message | System prompts become cached prefix |
| Session-level metrics | Track cumulative effectiveness |
| Prometheus + OpenTelemetry | Standard observability format |
| 90% cached token discount | Reflects Gemini's actual pricing |
| 1-hour default TTL | Balance hit rate vs freshness |